

Cloud Engineer

En este nuevo artículo vamos a hablar de uno de nuestros partners: Starburst[1]. Starburst es la versión empresarial de Trino[2] realizando nuevas integraciones, mejoras de rendimiento, una capa de seguridad y restando complejidad a la gestión con una interfaz de usuario muy fácil de usar y que te permite realizar distintas configuraciones.
Para los que no conocéis Trino, es un motor de consulta SQL distribuido open-source creado en 2012 por Facebook bajo el nombre Presto. Está diseñado para consultar grandes conjuntos de datos distribuidos en una o más fuentes de datos heterogéneas. Esto significa que podemos consultar datos que residen en diferentes sistemas de almacenamiento como HDFS, AWS S3, Google Cloud Storage o Azure Blob Storage. Trino también tiene la capacidad de federar diferentes fuentes de datos como MySQL, PostgreSQL, Cassandra, Kafka.
Con las nuevas necesidades que van saliendo de arquitecturas orientadas al Data Mesh[3], plataformas analíticas como Starburst son cada vez más importantes y nos permiten centralizar y federar distintas fuentes de datos para así tener solo un punto de entrada a nuestra información. Con esta mentalidad, podemos hacer que nuestros usuarios accedan a la plataforma de Starburst con distintos roles y distinta granularidad de acceso para que puedan consultar los distintos dominios que poseen las empresas. Además Starburst no solo se queda en la consulta de datos, sino que nos permite conectarnos con herramientas analíticas como puedes ser DBT[4] o Jupyter Notebook[5] o herramientas de reporting como Power BI[6] para sacarle más rendimiento a todos nuestros datos. Pero Starburst no solo se queda en eso, sino que nos puede ayudar en la migraciones de datos hacia el Cloud, ya que fácilmente podemos conectarnos a las fuentes de datos y sacar toda la información para volcarlas en cualquier almacenamiento del Cloud.
Como podéis observar, Starburst es capaz de analizar todos sus datos, dentro y alrededor de tu Data Lake, y se conecta a todo un ecosistema de herramientas. Por eso vamos a realizar una serie de artículos para tratar los puntos más relevantes como son el despliegue y configuración de la plataforma, integración con otras herramientas y gobierno y administración de usuarios. En este primer artículo, nos vamos a centrar en el despliegue de Starburst en Kubernetes, así como la configuración que se tiene que realizar para conectar con los distintos componentes de GCP. Además hemos añadido una capa de monitorización con Prometheus[7] y Grafana[8], donde hemos publicado un dashboard con distintas métricas importantes por si cualquier compañía quiere centralizar las métricas en Grafana. Para todo ello, nos vamos a apoyar de un repositorio que hemos creado con el levantamiento de la infraestructura y la instalación de Starburst.

Como se puede observar en el diagrama, estos son los componentes que se van a desplegar para la configuración de Starburst. Como pieza central del despliegue, utilizaremos Google Kubernetes Engine. Este es el servicio administrado de orquestación de contenedores de Google. Utilizaremos Kubernetes ya que nos facilitará la gestión de Starburst y aprovecharemos las ventajas del autoscaling de Kubernetes para ampliar el número de workers de Starburst y escalar en más nodos para poder así tener más recursos de computación si tenemos algún pico de trabajo o de usuarios.
Como configuración inicial de nuestro cluster de GKE, comenzaremos con un único nodepool para facilitar el despliegue. Un nodepool es una agrupación de nodos dentro de un cluster con la misma configuración y especificaciones de tipo de máquina. En nuestro caso, nuestro nodepool se llamará `default-node-pool` y el tipo de instancia utilizada será `e2-standard-16`, que es la recomendada por Starburst, ya que el tipo de carga de trabajo necesita nodos con bastante memoria. Además de la instalación de Starburst, también desplegaremos en el cluster tanto Prometheus como Grafana.
Como hemos explicado anteriormente, Starburst está basado en Trino, que es un motor de consulta distribuido. Los principales componentes de Trino son el Coordinator y los Workers. El Coordinator de Trino es el componente responsable de analizar las sentencias, planificar las consultas y gestionar los nodos Workers de Trino. El Coordinator realiza un seguimiento de la actividad de cada Worker y orquesta la ejecución de una consulta. Los Workers son el componente responsable de ejecutar tareas y procesar datos. Los nodos Workers obtienen datos de los conectores e intercambian datos intermedios entre sí. El Coordinator es responsable de obtener los resultados de los Workers y devolver los resultados finales al cliente.
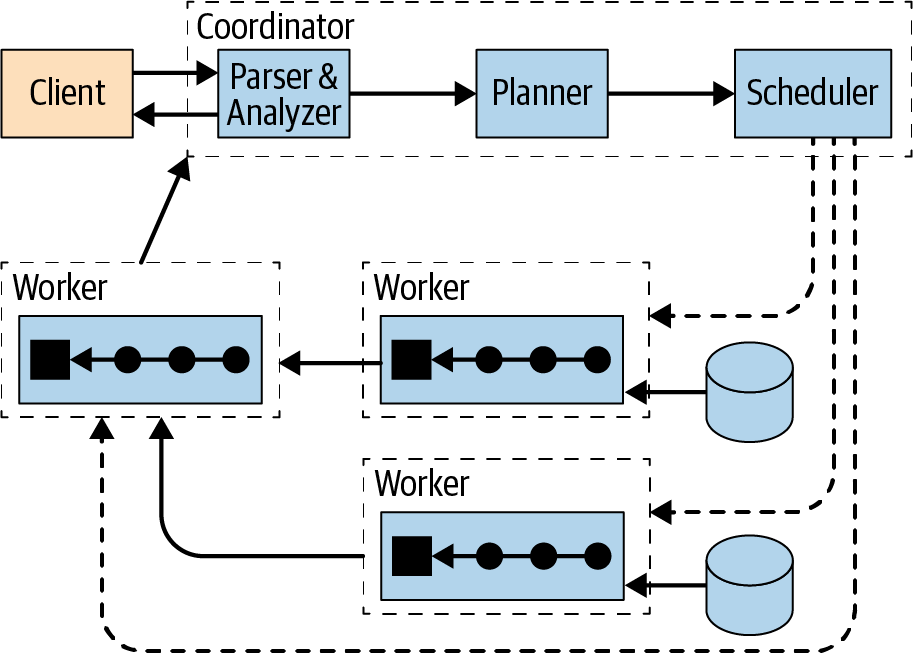
Como componentes transversales de nuestra arquitectura, también desplegaremos una red con una subnet para realizar el despliegue de nuestro cluster de GKE, así como un bucket en Cloud Storage para realizar pruebas de escritura de datos desde Starburst.
Además, como componente fuera de la arquitectura, tendremos jmeter[10], la herramienta con la que realizaremos pruebas de performance para probar la elasticidad de Starburst y poder probar el autoescalado de nuestro cluster.
Una vez explicada la arquitectura vamos a proceder a realizar el despliegue de todos los componentes. Para ello, nos vamos a ayudar de Terraform como herramienta de IaC. Como partes importantes de este despliegue, tendremos la parte más de infraestructura tradicional que son las VPC, el cluster de GKE y la parte de Cloud Storage como hemos hablado antes, además de los componentes que desplegamos en Kubernetes de una forma totalmente automatizada que son Grafana y Prometheus.
Vamos a empezar con la explicación de la infraestructura más clásica. Para este despliegue haremos uso de dos módulos que están subidos al github:
Estos dos módulos están invocados en el `main.tf` del repositorio y hacen uso del provider de Google para el despliegue:
```tf
provider "google" {
project = var.project_id
region = var.region
}
provider "google-beta" {
project = var.project_id
region = var.region
}
module "network" {
source = "git@github.com:lucasberlang/gcp-network.git?ref=v1.0.0"
project_id = var.project_id
description = var.description
enable_nat_gateway = true
offset = 1
intra_subnets = [
{
subnet_name = "private-subnet01"
subnet_ip_cidr = "10.0.0.0/24"
subnet_private_access = false
subnet_region = var.region
}
]
secondary_ranges = {
private-subnet01 = [
{
range_name = "private-subnet01-01"
ip_cidr_range = var.ip_range_pods
},
{
range_name = "private-subnet01-02"
ip_cidr_range = var.ip_range_services
},
]
}
labels = var.labels
}
resource "google_storage_bucket" "gcs_starburst" {
name = var.name
location = "EU"
force_destroy = var.force_destroy
}
module "gke-starburst" {
source = "git@github.com:lucasberlang/gcp-gke.git?ref=v1.1.0"
project_id = var.project_id
name = "starburst"
regional = true
region = var.region
network = module.network.network_name
subnetwork = "go-euw1-bt-stb-private-subnet01-dev"
ip_range_pods = "private-subnet01-01"
ip_range_services = "private-subnet01-02"
enable_private_endpoint = false
enable_private_nodes = false
master_ipv4_cidr_block = "172.16.0.0/28"
workload_identity = false
kubernetes_version = var.kubernetes_version
gce_persistent_disk_csi_driver = true
master_authorized_networks = [
{
cidr_block = module.network.intra_subnet_ips.0
display_name = "VPC"
},
{
cidr_block = "0.0.0.0/0"
display_name = "shell"
}
]
cluster_autoscaling = {
enabled = true,
autoscaling_profile = "BALANCED",
max_cpu_cores = 300,
max_memory_gb = 940,
min_cpu_cores = 24,
min_memory_gb = 90,
}
node_pools = [
{
name = "default-node-pool"
machine_type = "e2-standard-16"
auto_repair = false
auto_upgrade = false
},
]
node_labels = {
"starburstpool" = "default-node-pool"
}
istio = var.istio
dns_cache = var.dns_cache
labels = var.labels
}
```
Lo único importante a tener en cuenta, es que vamos a desplegar una red con una única subred y que el cluster de GKE está habilitado con el autoescalado para poder incrementar el número de nodos cuando haya una carga de trabajo. Asimismo, es importante tener en cuenta que se ha añadido una etiqueta a todos los nodos que es `”starburstpool” = “default-node-pool”` para aislar el propio despliegue de Starburst del que más tarde haremos uso. Aparte de estos componentes también desplegamos una Cloud Storage para luego configurar el conector de Hive.
Por otra parte, como hemos comentado, también haremos el despliegue de Grafana y Prometheus. Para ello haremos uso del provider de Helm y de Kubernetes de Terraform.
El despliegue de estos componentes lo tenemos en el archivo `helm.tf`:
```tf
resource "kubernetes_namespace" "prometheus" {
metadata {
name = "prometheus"
}
}
resource "kubernetes_namespace" "grafana" {
metadata {
name = "grafana"
}
}
resource "helm_release" "grafana" {
chart = "grafana"
name = "grafana"
namespace = kubernetes_namespace.grafana.metadata.0.name
repository = "https://grafana.github.io/helm-charts"
values = [
file("templates/grafana.yaml")
]
}
resource "kubernetes_secret" "grafana-secrets" {
metadata {
name = "grafana-credentials"
namespace = kubernetes_namespace.grafana.metadata.0.name
}
data = {
adminUser = "admin"
adminPassword = "admin"
}
}
resource "helm_release" "prometheus" {
chart = "prometheus"
name = "prometheus"
namespace = kubernetes_namespace.prometheus.metadata.0.name
repository = "https://prometheus-community.github.io/helm-charts"
values = [
file("templates/prometheus.yaml")
]
}
```
Hay varias cosas que tenemos que tener en cuenta, estas son las configuraciones que hemos añadido en los values de cada chart.
Primero vamos con los valores de Prometheus que hemos configurado. Hemos añadido una configuración extra para que recoja las métricas de Starburst una vez que se levante. Esto lo hemos hecho en la siguiente parte de la configuración:
```yaml
extraScrapeConfigs: |
- job_name: starburst-monitor
scrape_interval: 5s
static_configs:
- targets:
- 'prometheus-coordinator-starburst-enterprise.default.svc.cluster.local:8081'
- 'prometheus-worker-starburst-enterprise.default.svc.cluster.local:8081'
metrics_path: /metrics
scheme: http
```
Lo único a tener en cuenta son los targets que hemos añadido, que básicamente son los servicios tanto del Coordinator como de los Workers de Starburst para que recoja todas las métricas.
En la parte de Grafana hemos añadido tanto la configuración de Prometheus, como un dashboard que hemos creado custom para Starburst.
La configuración que hemos añadida es la siguiente:
```yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-server.prometheus.svc.cluster.local
isDefault: true
dashboards:
default:
Starburst-cluster:
gnetId: 18767
revision: 1
datasource: Prometheus
```
En la carpeta infra del repositorio de Github, podrás encontrar todo el código necesario para realizar dicho despliegue.
Una vez que tengamos toda la infraestructura levantada, vamos a proceder a desplegar Starburst en nuestro cluster de GKE. Para ello, vamos a desplegar estos componentes:
El servicio de Hive Mestastore es necesario para configurar el conector de Hive para así poder acceder o escribir a los datos que se guardan en Google Cloud Storage. Como backend de nuestro servicio de Metastore, vamos a desplegar un base de datos PostgreSQL, para así poder guardar toda la información de la metadata en esta base de datos. Además tendremos que configurar el servicio de Hive para pasarle las credenciales de Google Cloud y que tenga permisos para poder leer y escribir de GCS. Por lo tanto, vamos a proceder primero a declarar algunas variables de entorno que necesitaremos para descargar los charts del repositorio privado de Starburst y algunas variables de configuración más que necesitaremos para realizar el despliegue.
Esta serían las variables que vamos a necesitar en nuestro despliegue:
```bash
export admin_usr= # Choose an admin user name you will use to login to Starburst & Ranger. Do NOT use 'admin'
export admin_pwd= # Choose an admin password you will use to login to Starburst & Ranger. MUST be a minimum of 8 characters and contain at least one uppercase, lowercase and numeric value.
export registry_pwd= #Credentials harbor registry
export registry_usr= #Credentials harbor registry
export starburst_license=starburstdata.license #License Starburst
# Zone where the cluster will be deployed. e.g. us-east4-b
export zone="europe-west1"
# Google Cloud Project ID where the cluster is being deployed
export google_cloud_project=
# Google Service account name. The service account is used to access services like GCS and BigQuery, so you should ensure that it has the relevant permissions for these
# Give your cluster a name
export cluster_name=
# These next values are automatically set based on your input values
# We'll automatically get the domain for the zone you are selecting. Comment this out if you don't need DNS
#export google_cloud_dns_zone_name=$(gcloud dns managed-zones describe ${google_cloud_dns_zone:?Zone not set} --project ${google_cloud_project_dns:?Project ID not set} | grep dnsName | awk '{ print $2 }' | sed 's/.$//g')
# This is the public URL to access Starburst
export starburst_url=${cluster_name:?Cluster Name not set}-starburst.${google_cloud_dns_zone_name}
# This is the public URL to access Ranger
export ranger_url=${cluster_name:?Cluster Name not set}-ranger.${google_cloud_dns_zone_name}
# Insights DB details
# These are the defaults if you choose to deploy your postgresDB to the K8s cluster
# You can adjust these to connect to an external DB, but be advised that the nodes in the K8s cluster must have access to the URL
export database_connection_url=jdbc:postgresql://postgresql:5432/insights
export database_username=
export database_password=
# Data Products. Leave the password unset as below, if you are connecting directly to the coordinator on port 8080
export data_products_enabled=true
export data_products_jdbc_url=jdbc:trino://coordinator:8080
export data_products_username=${admin_usr}
export data_products_password=
# Starburst Access Control
export starburst_access_control_enabled=true
export starburst_access_control_authorized_users=${admin_usr}
# These last remaining values are static
export xtra_args_hive="--set objectStorage.gs.cloudKeyFileSecret=service-account-key"
export xtra_args_starburst="--values starburst.catalog.yaml"
export xtra_args_ranger=""
```
Una vez definidas nuestras variables de entorno procederemos a crearnos un secreto de Kubernetes para configurar las credenciales con las que Hive se va a conectar a GCS.
```bash
kubectl create secret generic service-account-key --from-file key.json
```
Para ello, como paso previo, nos hemos creado una service account con permisos en Cloud Storage y en Bigquery y nos hemos descargado las credenciales de esa service account. También como paso previo, añadiremos los repositorio de Helm con el siguiente comando:
```bash
helm repo add --username ${registry_usr} --password ${registry_pwd} starburstdata https://harbor.starburstdata.net/chartrepo/starburstdata
helm repo add bitnami https://charts.bitnami.com/bitnami
```
Una vez que tenemos la configuración previa hecha, vamos a proceder a desplegar el servicio de PostgreSQL primero, y posteriormente, el Hive Metastore. Para ello haremos uso de Helm. Para el despliegue de PostgreSQL usaremos el siguiente comando:
```bash
helm upgrade postgres bitnami/postgresql --install --values postgres.yaml \
--version 12.1.6 \
--set primary.nodeSelector.starburstpool=default-node-pool \
--set readReplicas.nodeSelector.starburstpool=default-node-pool
```
Hay varios factores a tener en cuenta en el comando anterior. El primero es que el despliegue de PostgreSQL lo haremos en los nodos que tengan el tag `starburstpool=default-node-pool`, que es nuestro worker pool por defecto. Usaremos la versión 12.1.6 de PostgreSQL y la configuración que hemos añadido en postgres es la siguiente:
```yaml
fullnameOverride: postgresql
global:
postgresql:
auth:
database: postgres
username: postgres
postgresPassword: ****
storageClass: "standard"
primary:
initdb:
scripts:
init.sql: |
create database hive;
create database ranger;
create database insights;
create database datacache;
service:
type: ClusterIP
``` Esta información se encuentra en el archivo `postgres.yaml` y nos configurará el usuario y contraseña de PostgreSQL, y nos creará 4 bases de datos que usa internamente Starburst como backend. En nuestro caso, como podéis observar, hemos configurado el servicio de backend en el mismo cluster que la configuración de Starburst, pero esto se puede configurar fuera del cluster de Kubernetes para entornos productivos. Básicamente podríamos tener un servicio gestionado como es Cloud Sql para así evitar problemas en producción.
Ahora vamos a proceder con el despliegue del servicio de Hive Metastore, esto lo haremos con el siguiente comando:
```bash
helm upgrade hive starburstdata/starburst-hive --install --values hive.yaml \
--set registryCredentials.username=${registry_usr:?Value not set} \
--set registryCredentials.password=${registry_pwd:?Value not set} \
--set nodeSelector.starburstpool=default-node-pool \
--set objectStorage.gs.cloudKeyFileSecret=service-account-key
``` Aquí tenemos que tener en cuenta varias cosas importantes, la primera es que como en el servicio de PostgreSQL el despliegue se va a realizar en los nodos con el tag `starburstpool=default-node-pool`. El segundo punto importante es que hemos realizado la configuración de las credenciales de Google para que funcione el conector de hive, esto lo hemos realizado con el siguiente comando:
`--set objectStorage.gs.cloudKeyFileSecret=service-account-key` Con esta acción, montamos el fichero de credenciales como un archivo en el despliegue de Hive para que tenga visibilidad en las credenciales. Los valores extras que hemos añadido a la configuración de hive se encuentran en el archivo `hive.yaml` y son los siguientes:
```yaml
database:
external:
driver: org.postgresql.Driver
jdbcUrl: jdbc:postgresql://postgresql:5432/hive
user: #user postgres
password: #password postgres
type: external
expose:
type: clusterIp
image:
repository: harbor.starburstdata.net/starburstdata/hive
registryCredentials:
enabled: true
registry: harbor.starburstdata.net/starburstdata
```
Una vez que tenemos desplegado tanto el servicio de Postgres como el de Hive Metastore, podemos proceder a desplegar Starburst. Primero necesitaremos realizar una serie de pasos previos. El primero será crearnos un secreto de Kubernetes con la licencia de Starburst, el segundo será crearnos un secreto con las variables de entornos que hemos definido antes, esto lo haremos con un pequeño script para quitar complejidad y que nos coja las variables que ya hemos definido.
Con el siguiente comando procederemos a realizar los pasos anteriores:
```bash
kubectl create secret generic starburst --from-file ${starburst_license}
chmod 755 load_secrets.sh && . ./load_secrets.sh
kubectl apply -f secrets.yaml
```
Una vez que tenemos las configuraciones previas vamos a proceder a desplegar Starburst con el siguiente comando:
```bash
helm upgrade starburst-enterprise starburstdata/starburst-enterprise --install --values starburst.yaml \
--set sharedSecret="$(openssl rand 64 | base64)" \
--set coordinator.resources.requests.memory=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.memory}' | awk -F "Ki" '{ print $1 }')*10/100 ))Ki) \
--set coordinator.resources.requests.cpu=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.cpu}' | awk -F "m" '{ print $1 }')*10/100 ))m) \
--set coordinator.resources.limits.memory=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.memory}' | awk -F "Ki" '{ print $1 }')*10/100 ))Ki) \
--set coordinator.resources.limits.cpu=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.cpu}' | awk -F "m" '{ print $1 }')*10/100 ))m) \
--set worker.resources.requests.memory=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.memory}' | awk -F "Ki" '{ print $1 }') - 10500000 ))Ki) \
--set worker.resources.requests.cpu=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.cpu}' | awk -F "m" '{ print $1 }') - 3500 ))m) \
--set worker.resources.limits.memory=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.memory}' | awk -F "Ki" '{ print $1 }') - 10500000 ))Ki) \
--set worker.resources.limits.cpu=$(echo $(( $(kubectl get nodes --selector='starburstpool=default-node-pool' -o jsonpath='{.items[0].status.allocatable.cpu}' | awk -F "m" '{ print $1 }') - 3500 ))m) \
--set coordinator.nodeSelector.starburstpool=default-node-pool
```
Aquí como podéis observar, hay varias cosas a tener en cuenta. La primera es que todos los componentes de Starburst que se despliegan lo hacen en los nodos con el tag `starburstpool=default-node-pool`. Esto simplemente lo hemos hecho para quitar complejidad a la demo. En entornos productivos, una buena práctica sería tener un nodepool para el Coordinator y otro nodepool para los Workers de Starburst.
Otra cosa a tener en cuenta es la configuración de la memoria y cpu que se hace tanto en los Workers como en el Coordinator. Como buenas prácticas, Starburst recomienda que haya un pod worker por cada nodo que se despliega en nuestro cluster de Kubernetes. Para ello lo que hemos hecho es ajustar la memoria y cpu de nuestros pods al tamaño de máquina que tenemos. Por último están los valores de configuración que hemos utilizado en el despliegue de Starburst, estos se pueden encontrar en el archivo `starburst.yaml` y son los siguientes:
```yaml
catalogs:
hive: |
connector.name=hive
hive.security=starburst
hive.metastore.uri=thrift://hive:9083
hive.gcs.json-key-file-path=/gcs-keyfile/key.json
hive.gcs.use-access-token=false
postgres: |
connector.name=postgresql
connection-url=jdbc:postgresql://postgresql:5432/insights
connection-user=******
connection-password=******
bigquery: |
connector.name=bigquery
bigquery.project-id=******
bigquery.credentials-file=/gcs-keyfile/key.json
prometheus:
enabled: true
agent:
version: "0.16.1"
port: 8081
config: "/etc/starburst/telemetry/prometheus.yaml"
rules:
- pattern: trino.execution<name=QueryManager><>(running_queries|queued_queries)
name: $1
attrNameSnakeCase: true
type: GAUGE
- pattern: 'trino.execution<name=QueryManager><>FailedQueries\.TotalCount'
name: 'starburst_failed_queries'
type: COUNTER
- pattern: 'trino.execution<name=QueryManager><>(running_queries)'
name: 'starburst_running_queries'
- pattern: 'trino.execution<name=QueryManager><>StartedQueries\.FiveMinute\.Count'
name: 'starburst_started_queries'
- pattern: 'trino.execution<name=SqlTaskManager><>InputPositions\.FiveMinute\.Count'
name: 'starburst_input_rows'
- pattern: 'trino.execution<name=SqlTaskManager><>InputDataSize\.FiveMinute\.Count'
name: 'starburst_input_data_bytes'
- pattern: 'trino.execution<name=QueryManager><>UserErrorFailures\.FiveMinute\.Count'
name: 'starburst_failed_queries_user'
- pattern: 'trino.execution<name=QueryManager><>ExecutionTime\.FiveMinutes\.P50'
name: 'starburst_latency_p50'
- pattern: 'trino.execution<name=QueryManager><>WallInputBytesRate\.FiveMinutes\.P90'
name: 'starburst_latency_p90'
- pattern: 'trino.failuredetector<name=HeartbeatFailureDetector><>ActiveCount'
name: 'starburst_active_node'
- pattern: 'trino.memory<type=ClusterMemoryPool, name=general><>FreeDistributedBytes'
name: 'starburst_free_memory_pool'
- pattern: 'trino.memory<name=ClusterMemoryManager><>QueriesKilledDueToOutOfMemory'
name: 'starburst_queries_killed_due_to_out_of_memory'
- pattern: 'java.lang<type=Memory><HeapMemoryUsage>committed'
name: 'starburst_heap_size_usage'
- pattern: 'java.lang<type=Threading><>ThreadCount'
name: 'starburst_thread_count'
coordinator:
envFrom:
- secretRef:
name: environment-vars
additionalProperties: |
starburst.data-product.enabled=${ENV:data_products_enabled}
data-product.starburst-jdbc-url=${ENV:data_products_jdbc_url}
data-product.starburst-user=${ENV:data_products_username}
data-product.starburst-password=
query.max-memory=1PB
starburst.access-control.enabled=${ENV:starburst_access_control_enabled}
starburst.access-control.authorized-users=${ENV:starburst_access_control_authorized_users}
etcFiles:
properties:
config.properties: |
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
discovery-server.enabled=true
discovery.uri=http://localhost:8080
usage-metrics.cluster-usage-resource.enabled=true
http-server.authentication.allow-insecure-over-http=true
web-ui.enabled=true
http-server.process-forwarded=true
insights.persistence-enabled=true
insights.metrics-persistence-enabled=true
insights.jdbc.url=${ENV:database_connection_url}
insights.jdbc.user=${ENV:database_username}
insights.jdbc.password=${ENV:database_password}
password-authenticator.properties: |
password-authenticator.name=file
nodeSelector:
starburstpool: default-node-pool
resources:
limits:
cpu: 2
memory: 12Gi
requests:
cpu: 2
memory: 12Gi
expose:
type: clusterIp
ingress:
serviceName: starburst
servicePort: 8080
host:
path: "/"
pathType: Prefix
tls:
enabled: true
secretName: tls-secret-starburst
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: letsencrypt
registryCredentials:
enabled: true
password: ******
registry: harbor.starburstdata.net/starburstdata
username: ******
starburstPlatformLicense: starburst
userDatabase:
enabled: true
users:
- password: ******
username: ******
worker:
envFrom:
- secretRef:
name: environment-vars
autoscaling:
enabled: true
maxReplicas: 10
minReplicas: 3
targetCPUUtilizationPercentage: 40
deploymentTerminationGracePeriodSeconds: 30
nodeSelector:
starburstpool: default-node-pool
resources:
limits:
cpu: 8
memory: 40Gi
requests:
cpu: 8
memory: 40Gi
starburstWorkerShutdownGracePeriodSeconds: 120
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Exists"
effect: "NoSchedule"
additionalVolumes:
- path: /gcs-keyfile/key.json
subPath: key.json
volume:
configMap:
name: "sa-key"
```
En esta configuración hay varios valores a tener en cuenta, como son catalogs, prometheus, worker y additionalVolumes.
Vamos a empezar explicando la parte de catalogs. Para los que no lo sepan, un catálogo en Starburst es la configuración que permite acceder a unas fuentes de datos determinadas. Cada clúster de Starburst puede tener configurados múltiples catálogos y, por tanto, permitir el acceso a diversas fuentes de datos. En nuestro caso hemos definido el catálogo de Hive, PostgreSQL y Bigquery para poder acceder a dichas fuentes de datos:
```yaml
catalogs:
hive: |
connector.name=hive
hive.security=starburst
hive.metastore.uri=thrift://hive:9083
hive.gcs.json-key-file-path=/gcs-keyfile/key.json
hive.gcs.use-access-token=false
postgres: |
connector.name=postgresql
connection-url=jdbc:postgresql://postgresql:5432/insights
connection-user=******
connection-password=******
bigquery: |
connector.name=bigquery
bigquery.project-id=******
bigquery.credentials-file=/gcs-keyfile/key.json
```
La segunda configuración a tener en cuenta es la de Prometheus, esto lo realizamos para exponer ciertas métricas a Prometheus y poder sacar información relevante en un dashboard de Grafana. Para ello tenemos la siguiente configuración:
```yaml
prometheus:
enabled: true
agent:
version: "0.16.1"
port: 8081
config: "/etc/starburst/telemetry/prometheus.yaml"
rules:
- pattern: trino.execution<name=QueryManager><>(running_queries|queued_queries)
name: $1
attrNameSnakeCase: true
type: GAUGE
- pattern: 'trino.execution<name=QueryManager><>FailedQueries\.TotalCount'
name: 'starburst_failed_queries'
type: COUNTER
- pattern: 'trino.execution<name=QueryManager><>(running_queries)'
name: 'starburst_running_queries'
- pattern: 'trino.execution<name=QueryManager><>StartedQueries\.FiveMinute\.Count'
name: 'starburst_started_queries'
- pattern: 'trino.execution<name=SqlTaskManager><>InputPositions\.FiveMinute\.Count'
name: 'starburst_input_rows'
- pattern: 'trino.execution<name=SqlTaskManager><>InputDataSize\.FiveMinute\.Count'
name: 'starburst_input_data_bytes'
- pattern: 'trino.execution<name=QueryManager><>UserErrorFailures\.FiveMinute\.Count'
name: 'starburst_failed_queries_user'
- pattern: 'trino.execution<name=QueryManager><>ExecutionTime\.FiveMinutes\.P50'
name: 'starburst_latency_p50'
- pattern: 'trino.execution<name=QueryManager><>WallInputBytesRate\.FiveMinutes\.P90'
name: 'starburst_latency_p90'
- pattern: 'trino.failuredetector<name=HeartbeatFailureDetector><>ActiveCount'
name: 'starburst_active_node'
- pattern: 'trino.memory<type=ClusterMemoryPool, name=general><>FreeDistributedBytes'
name: 'starburst_free_memory_pool'
- pattern: 'trino.memory<name=ClusterMemoryManager><>QueriesKilledDueToOutOfMemory'
name: 'starburst_queries_killed_due_to_out_of_memory'
- pattern: 'java.lang<type=Memory><HeapMemoryUsage>committed'
name: 'starburst_heap_size_usage'
- pattern: 'java.lang<type=Threading><>ThreadCount'
name: 'starburst_thread_count'
```
En la configuración de los workers, vamos a activar el autoescalado de estos pods. Para ello vamos a realizar una configuración para que haya un mínimo de 3 pods workers que se traducirán en 3 nodos en nuestro cluster de GKE y un máximo de 10 pods. Para el autoescalado vamos a usar la métrica de consumo de CPU.
Los valores son los siguientes:
```yaml
worker:
envFrom:
- secretRef:
name: environment-vars
autoscaling:
enabled: true
maxReplicas: 10
minReplicas: 3
targetCPUUtilizationPercentage: 40
```
Por último, añadiremos un volumen adicional a nuestro despliegue para poder montar las credenciales de Google cloud tanto en el coordinator como en los workers.
Esto lo haremos de la siguiente forma:
```yaml
additionalVolumes:
- path: /gcs-keyfile/key.json
subPath: key.json
volume:
configMap:
name: "sa-key"
```
Con todos estos pasos, tendríamos nuestro cluster de Starburst ya operativo.

Una vez realizado el levantamiento del cluster de Starburst, vamos a realizar algunas consultas para probar su rendimiento y funcionamiento. Para ello vamos a realizar consultas de lectura en el esquema de TPCH[13] y después vamos a escribir la salida de estas consultas en el bucket de Google que hemos creado en los pasos de despliegue.
Las consultas que vamos a ejecutar se encuentran en la carpeta de queries en los archivos `tpch.sql` y `gcs_storage.sql`.
Para lanzar las consultas será tan sencillo como irnos al apartado de consultas de la interfaz web y ejecutar las primeras consultas del archivo `tpch.sql`:
```sql
CREATE SCHEMA hive.logistic WITH (location = 'gs://starburst-bluetab-test/logistic');
CREATE VIEW "hive"."logistic"."shipping_priority" SECURITY DEFINER AS
SELECT
l.orderkey
, SUM((l.extendedprice * (1 - l.discount))) revenue
, o.orderdate
, o.shippriority
FROM
tpch.tiny.customer c
, tpch.tiny.orders o
, tpch.tiny.lineitem l
WHERE ((c.mktsegment = 'BUILDING') AND (c.custkey = o.custkey) AND (l.orderkey = o.orderkey))
GROUP BY l.orderkey, o.orderdate, o.shippriority
ORDER BY revenue DESC, o.orderdate ASC;
CREATE VIEW "hive"."logistic"."minimum_cost_supplier" SECURITY DEFINER AS
SELECT
s.acctbal
, s.name SupplierName
, n.name Nation
, p.partkey
, p.mfgr
, s.address
, s.phone
, s.comment
FROM
tpch.tiny.part p
, tpch.tiny.supplier s
, tpch.tiny.partsupp ps
, tpch.tiny.nation n
, tpch.tiny.region r
WHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (p.size = 15) AND (p.type LIKE '%BRASS') AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE') AND (ps.supplycost = (SELECT MIN(ps.supplycost)
FROM
tpch.tiny.partsupp ps
, tpch.tiny.supplier s
, tpch.tiny.nation n
, tpch.tiny.region r
WHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE'))
)))
ORDER BY s.acctbal DESC, n.name ASC, s.name ASC, p.partkey ASC;
select
cst.name as CustomerName,
cst.address,
cst.phone,
cst.nationkey,
cst.acctbal as BookedOrders,
cst.mktsegment,
nat.name as Nation,
reg.name as Region
from tpch.sf1.customer as cst
join tpch.sf1.nation as nat on nat.nationkey = cst.nationkey
join tpch.sf1.region as reg on reg.regionkey = nat.regionkey
where reg.regionkey = 1;
select
nat.name as Nation,
avg(cst.acctbal) as average_booking
from tpch.sf100.customer as cst
join tpch.sf100.nation as nat on nat.nationkey = cst.nationkey
join tpch.sf100.region as reg on reg.regionkey = nat.regionkey
where reg.regionkey = 1
group by nat.name;
```
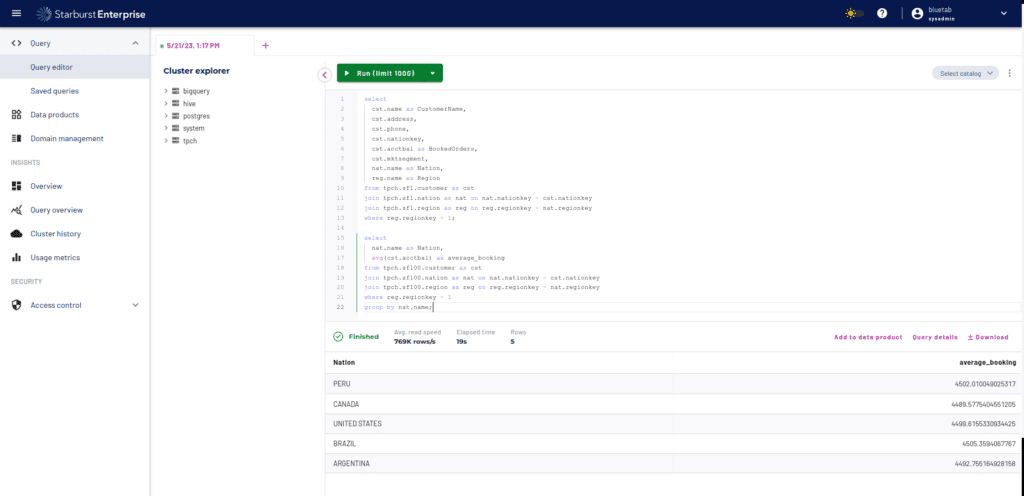
En estas pruebas crearemos una serie de vistas y haremos unos selects con varios cruces sobre las tablas de customer(15000000 rows), nation(25 rows) y region(5 rows) del esquema sf100 para comprobar que todo funciona correctamente y ver que tenemos nuestra plataforma operativa. Una vez comprobado que todo es correcto, probaremos a escribir algunos resultados en el bucket que hemos creado.
Para ello lanzaremos las consultas que se encuentran en el archivo `gcs_storage.sql`:
{"type":"elementor","siteurl":"https://beta.bluetab.net/wp-json/","elements":[{"id":"1a82503","elType":"widget","isInner":false,"isLocked":false,"settings":{"code_language":"python","code_block":"```sql\n CREATE SCHEMA hive.logistic WITH (location = 'gs://starburst-bluetab-test/logistic');\n\nCREATE VIEW \"hive\".\"logistic\".\"shipping_priority\" SECURITY DEFINER AS\nSELECT\n l.orderkey\n, SUM((l.extendedprice * (1 - l.discount))) revenue\n, o.orderdate\n, o.shippriority\nFROM\n tpch.tiny.customer c\n, tpch.tiny.orders o\n, tpch.tiny.lineitem l\nWHERE ((c.mktsegment = 'BUILDING') AND (c.custkey = o.custkey) AND (l.orderkey = o.orderkey))\nGROUP BY l.orderkey, o.orderdate, o.shippriority\nORDER BY revenue DESC, o.orderdate ASC;\n\n\nCREATE VIEW \"hive\".\"logistic\".\"minimum_cost_supplier\" SECURITY DEFINER AS\nSELECT\n s.acctbal\n, s.name SupplierName\n, n.name Nation\n, p.partkey\n, p.mfgr\n, s.address\n, s.phone\n, s.comment\nFROM\n tpch.tiny.part p\n, tpch.tiny.supplier s\n, tpch.tiny.partsupp ps\n, tpch.tiny.nation n\n, tpch.tiny.region r\nWHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (p.size = 15) AND (p.type LIKE '%BRASS') AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE') AND (ps.supplycost = (SELECT MIN(ps.supplycost)\nFROM\n tpch.tiny.partsupp ps\n, tpch.tiny.supplier s\n, tpch.tiny.nation n\n, tpch.tiny.region r\nWHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE'))\n)))\nORDER BY s.acctbal DESC, n.name ASC, s.name ASC, p.partkey ASC;\n\n\n\nselect\n cst.name as CustomerName,\n cst.address,\n cst.phone,\n cst.nationkey,\n cst.acctbal as BookedOrders,\n cst.mktsegment,\n nat.name as Nation,\n reg.name as Region\nfrom tpch.sf1.customer as cst\njoin tpch.sf1.nation as nat on nat.nationkey = cst.nationkey\njoin tpch.sf1.region as reg on reg.regionkey = nat.regionkey\nwhere reg.regionkey = 1;\n\nselect\n nat.name as Nation,\n avg(cst.acctbal) as average_booking\nfrom tpch.sf100.customer as cst\njoin tpch.sf100.nation as nat on nat.nationkey = cst.nationkey\njoin tpch.sf100.region as reg on reg.regionkey = nat.regionkey\nwhere reg.regionkey = 1\ngroup by nat.name;\n```\n","_title":"","_margin":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_margin_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_margin_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_padding":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_padding_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_padding_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_element_width":"","_element_width_tablet":"","_element_width_mobile":"","_element_custom_width":{"unit":"%","size":"","sizes":[]},"_element_custom_width_tablet":{"unit":"px","size":"","sizes":[]},"_element_custom_width_mobile":{"unit":"px","size":"","sizes":[]},"_element_vertical_align":"","_element_vertical_align_tablet":"","_element_vertical_align_mobile":"","_position":"","_offset_orientation_h":"start","_offset_x":{"unit":"px","size":"0","sizes":[]},"_offset_x_tablet":{"unit":"px","size":"","sizes":[]},"_offset_x_mobile":{"unit":"px","size":"","sizes":[]},"_offset_x_end":{"unit":"px","size":"0","sizes":[]},"_offset_x_end_tablet":{"unit":"px","size":"","sizes":[]},"_offset_x_end_mobile":{"unit":"px","size":"","sizes":[]},"_offset_orientation_v":"start","_offset_y":{"unit":"px","size":"0","sizes":[]},"_offset_y_tablet":{"unit":"px","size":"","sizes":[]},"_offset_y_mobile":{"unit":"px","size":"","sizes":[]},"_offset_y_end":{"unit":"px","size":"0","sizes":[]},"_offset_y_end_tablet":{"unit":"px","size":"","sizes":[]},"_offset_y_end_mobile":{"unit":"px","size":"","sizes":[]},"_z_index":"","_z_index_tablet":"","_z_index_mobile":"","_element_id":"","_css_classes":"","motion_fx_motion_fx_scrolling":"","motion_fx_translateY_effect":"","motion_fx_translateY_direction":"","motion_fx_translateY_speed":{"unit":"px","size":4,"sizes":[]},"motion_fx_translateY_affectedRange":{"unit":"%","size":"","sizes":{"start":0,"end":100}},"motion_fx_translateX_effect":"","motion_fx_translateX_direction":"","motion_fx_translateX_speed":{"unit":"px","size":4,"sizes":[]},"motion_fx_translateX_affectedRange":{"unit":"%","size":"","sizes":{"start":0,"end":100}},"motion_fx_opacity_effect":"","motion_fx_opacity_direction":"out-in","motion_fx_opacity_level":{"unit":"px","size":10,"sizes":[]},"motion_fx_opacity_range":{"unit":"%","size":"","sizes":{"start":20,"end":80}},"motion_fx_blur_effect":"","motion_fx_blur_direction":"out-in","motion_fx_blur_level":{"unit":"px","size":7,"sizes":[]},"motion_fx_blur_range":{"unit":"%","size":"","sizes":{"start":20,"end":80}},"motion_fx_rotateZ_effect":"","motion_fx_rotateZ_direction":"","motion_fx_rotateZ_speed":{"unit":"px","size":1,"sizes":[]},"motion_fx_rotateZ_affectedRange":{"unit":"%","size":"","sizes":{"start":0,"end":100}},"motion_fx_scale_effect":"","motion_fx_scale_direction":"out-in","motion_fx_scale_speed":{"unit":"px","size":4,"sizes":[]},"motion_fx_scale_range":{"unit":"%","size":"","sizes":{"start":20,"end":80}},"motion_fx_transform_origin_x":"center","motion_fx_transform_origin_y":"center","motion_fx_devices":["desktop","tablet","mobile"],"motion_fx_range":"","motion_fx_motion_fx_mouse":"","motion_fx_mouseTrack_effect":"","motion_fx_mouseTrack_direction":"","motion_fx_mouseTrack_speed":{"unit":"px","size":1,"sizes":[]},"motion_fx_tilt_effect":"","motion_fx_tilt_direction":"","motion_fx_tilt_speed":{"unit":"px","size":4,"sizes":[]},"sticky":"","sticky_on":["desktop","tablet","mobile"],"sticky_offset":0,"sticky_offset_tablet":"","sticky_offset_mobile":"","sticky_effects_offset":0,"sticky_effects_offset_tablet":"","sticky_effects_offset_mobile":"","sticky_parent":"","_animation":"","_animation_tablet":"","_animation_mobile":"","animation_duration":"","_animation_delay":"","_transform_rotate_popover":"","_transform_rotateZ_effect":{"unit":"px","size":"","sizes":[]},"_transform_rotateZ_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateZ_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotate_3d":"","_transform_rotateX_effect":{"unit":"px","size":"","sizes":[]},"_transform_rotateX_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateX_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect":{"unit":"px","size":"","sizes":[]},"_transform_rotateY_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_perspective_effect":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translate_popover":"","_transform_translateX_effect":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scale_popover":"","_transform_keep_proportions":"yes","_transform_scale_effect":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_skew_popover":"","_transform_skewX_effect":{"unit":"px","size":"","sizes":[]},"_transform_skewX_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewX_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect":{"unit":"px","size":"","sizes":[]},"_transform_skewY_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_flipX_effect":"","_transform_flipY_effect":"","_transform_rotate_popover_hover":"","_transform_rotateZ_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_rotateZ_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateZ_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotate_3d_hover":"","_transform_rotateX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_rotateX_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateX_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_rotateY_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_perspective_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translate_popover_hover":"","_transform_translateX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scale_popover_hover":"","_transform_keep_proportions_hover":"yes","_transform_scale_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_skew_popover_hover":"","_transform_skewX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_skewX_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewX_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_skewY_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_flipX_effect_hover":"","_transform_flipY_effect_hover":"","_transform_transition_hover":{"unit":"px","size":"","sizes":[]},"motion_fx_transform_x_anchor_point":"","motion_fx_transform_x_anchor_point_tablet":"","motion_fx_transform_x_anchor_point_mobile":"","motion_fx_transform_y_anchor_point":"","motion_fx_transform_y_anchor_point_tablet":"","motion_fx_transform_y_anchor_point_mobile":"","_background_background":"","_background_color":"","_background_color_stop":{"unit":"%","size":0,"sizes":[]},"_background_color_b":"#f2295b","_background_color_b_stop":{"unit":"%","size":100,"sizes":[]},"_background_gradient_type":"linear","_background_gradient_angle":{"unit":"deg","size":180,"sizes":[]},"_background_gradient_position":"center center","_background_image":{"url":"","id":"","size":""},"_background_image_tablet":{"url":"","id":"","size":""},"_background_image_mobile":{"url":"","id":"","size":""},"_background_position":"","_background_position_tablet":"","_background_position_mobile":"","_background_xpos":{"unit":"px","size":0,"sizes":[]},"_background_xpos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_xpos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_ypos":{"unit":"px","size":0,"sizes":[]},"_background_ypos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_ypos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_attachment":"","_background_repeat":"","_background_repeat_tablet":"","_background_repeat_mobile":"","_background_size":"","_background_size_tablet":"","_background_size_mobile":"","_background_bg_width":{"unit":"%","size":100,"sizes":[]},"_background_bg_width_tablet":{"unit":"px","size":"","sizes":[]},"_background_bg_width_mobile":{"unit":"px","size":"","sizes":[]},"_background_video_link":"","_background_video_start":"","_background_video_end":"","_background_play_once":"","_background_play_on_mobile":"","_background_privacy_mode":"","_background_video_fallback":{"url":"","id":"","size":""},"_background_slideshow_gallery":[],"_background_slideshow_loop":"yes","_background_slideshow_slide_duration":5000,"_background_slideshow_slide_transition":"fade","_background_slideshow_transition_duration":500,"_background_slideshow_background_size":"","_background_slideshow_background_size_tablet":"","_background_slideshow_background_size_mobile":"","_background_slideshow_background_position":"","_background_slideshow_background_position_tablet":"","_background_slideshow_background_position_mobile":"","_background_slideshow_lazyload":"","_background_slideshow_ken_burns":"","_background_slideshow_ken_burns_zoom_direction":"in","_background_hover_background":"","_background_hover_color":"","_background_hover_color_stop":{"unit":"%","size":0,"sizes":[]},"_background_hover_color_b":"#f2295b","_background_hover_color_b_stop":{"unit":"%","size":100,"sizes":[]},"_background_hover_gradient_type":"linear","_background_hover_gradient_angle":{"unit":"deg","size":180,"sizes":[]},"_background_hover_gradient_position":"center center","_background_hover_image":{"url":"","id":"","size":""},"_background_hover_image_tablet":{"url":"","id":"","size":""},"_background_hover_image_mobile":{"url":"","id":"","size":""},"_background_hover_position":"","_background_hover_position_tablet":"","_background_hover_position_mobile":"","_background_hover_xpos":{"unit":"px","size":0,"sizes":[]},"_background_hover_xpos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_hover_xpos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_hover_ypos":{"unit":"px","size":0,"sizes":[]},"_background_hover_ypos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_hover_ypos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_hover_attachment":"","_background_hover_repeat":"","_background_hover_repeat_tablet":"","_background_hover_repeat_mobile":"","_background_hover_size":"","_background_hover_size_tablet":"","_background_hover_size_mobile":"","_background_hover_bg_width":{"unit":"%","size":100,"sizes":[]},"_background_hover_bg_width_tablet":{"unit":"px","size":"","sizes":[]},"_background_hover_bg_width_mobile":{"unit":"px","size":"","sizes":[]},"_background_hover_video_link":"","_background_hover_video_start":"","_background_hover_video_end":"","_background_hover_play_once":"","_background_hover_play_on_mobile":"","_background_hover_privacy_mode":"","_background_hover_video_fallback":{"url":"","id":"","size":""},"_background_hover_slideshow_gallery":[],"_background_hover_slideshow_loop":"yes","_background_hover_slideshow_slide_duration":5000,"_background_hover_slideshow_slide_transition":"fade","_background_hover_slideshow_transition_duration":500,"_background_hover_slideshow_background_size":"","_background_hover_slideshow_background_size_tablet":"","_background_hover_slideshow_background_size_mobile":"","_background_hover_slideshow_background_position":"","_background_hover_slideshow_background_position_tablet":"","_background_hover_slideshow_background_position_mobile":"","_background_hover_slideshow_lazyload":"","_background_hover_slideshow_ken_burns":"","_background_hover_slideshow_ken_burns_zoom_direction":"in","_background_hover_transition":{"unit":"px","size":"","sizes":[]},"_border_border":"","_border_width":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_width_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_width_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_color":"","_border_radius":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_box_shadow_box_shadow_type":"","_box_shadow_box_shadow":{"horizontal":0,"vertical":0,"blur":10,"spread":0,"color":"rgba(0,0,0,0.5)"},"_box_shadow_box_shadow_position":" ","_border_hover_border":"","_border_hover_width":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_hover_width_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_hover_width_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_hover_color":"","_border_radius_hover":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_hover_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_hover_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_box_shadow_hover_box_shadow_type":"","_box_shadow_hover_box_shadow":{"horizontal":0,"vertical":0,"blur":10,"spread":0,"color":"rgba(0,0,0,0.5)"},"_box_shadow_hover_box_shadow_position":" ","_border_hover_transition":{"unit":"px","size":"","sizes":[]},"_mask_switch":"","_mask_shape":"circle","_mask_image":{"url":"","id":"","size":""},"_mask_notice":"","_mask_size":"contain","_mask_size_tablet":"","_mask_size_mobile":"","_mask_size_scale":{"unit":"%","size":100,"sizes":[]},"_mask_size_scale_tablet":{"unit":"px","size":"","sizes":[]},"_mask_size_scale_mobile":{"unit":"px","size":"","sizes":[]},"_mask_position":"center center","_mask_position_tablet":"","_mask_position_mobile":"","_mask_position_x":{"unit":"%","size":0,"sizes":[]},"_mask_position_x_tablet":{"unit":"px","size":"","sizes":[]},"_mask_position_x_mobile":{"unit":"px","size":"","sizes":[]},"_mask_position_y":{"unit":"%","size":0,"sizes":[]},"_mask_position_y_tablet":{"unit":"px","size":"","sizes":[]},"_mask_position_y_mobile":{"unit":"px","size":"","sizes":[]},"_mask_repeat":"no-repeat","_mask_repeat_tablet":"","_mask_repeat_mobile":"","hide_desktop":"","hide_tablet":"","hide_mobile":"","_attributes":"","custom_css":""},"defaultEditSettings":{"defaultEditRoute":"content"},"elements":[],"widgetType":"elementor-syntax-highlighter","editSettings":{"defaultEditRoute":"content","panel":{"activeTab":"content","activeSection":"content_section"}},"htmlCache":"\t\t<div class=\"elementor-widget-container\">\n\t\t\t<pre><code class='language-python'>```sql\n CREATE SCHEMA hive.logistic WITH (location = 'gs://starburst-bluetab-test/logistic');\n\nCREATE VIEW "hive"."logistic"."shipping_priority" SECURITY DEFINER AS\nSELECT\n l.orderkey\n, SUM((l.extendedprice * (1 - l.discount))) revenue\n, o.orderdate\n, o.shippriority\nFROM\n tpch.tiny.customer c\n, tpch.tiny.orders o\n, tpch.tiny.lineitem l\nWHERE ((c.mktsegment = 'BUILDING') AND (c.custkey = o.custkey) AND (l.orderkey = o.orderkey))\nGROUP BY l.orderkey, o.orderdate, o.shippriority\nORDER BY revenue DESC, o.orderdate ASC;\n\n\nCREATE VIEW "hive"."logistic"."minimum_cost_supplier" SECURITY DEFINER AS\nSELECT\n s.acctbal\n, s.name SupplierName\n, n.name Nation\n, p.partkey\n, p.mfgr\n, s.address\n, s.phone\n, s.comment\nFROM\n tpch.tiny.part p\n, tpch.tiny.supplier s\n, tpch.tiny.partsupp ps\n, tpch.tiny.nation n\n, tpch.tiny.region r\nWHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (p.size = 15) AND (p.type LIKE '%BRASS') AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE') AND (ps.supplycost = (SELECT MIN(ps.supplycost)\nFROM\n tpch.tiny.partsupp ps\n, tpch.tiny.supplier s\n, tpch.tiny.nation n\n, tpch.tiny.region r\nWHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE'))\n)))\nORDER BY s.acctbal DESC, n.name ASC, s.name ASC, p.partkey ASC;\n\n\n\nselect\n cst.name as CustomerName,\n cst.address,\n cst.phone,\n cst.nationkey,\n cst.acctbal as BookedOrders,\n cst.mktsegment,\n nat.name as Nation,\n reg.name as Region\nfrom tpch.sf1.customer as cst\njoin tpch.sf1.nation as nat on nat.nationkey = cst.nationkey\njoin tpch.sf1.region as reg on reg.regionkey = nat.regionkey\nwhere reg.regionkey = 1;\n\nselect\n nat.name as Nation,\n avg(cst.acctbal) as average_booking\nfrom tpch.sf100.customer as cst\njoin tpch.sf100.nation as nat on nat.nationkey = cst.nationkey\njoin tpch.sf100.region as reg on reg.regionkey = nat.regionkey\nwhere reg.regionkey = 1\ngroup by nat.name;\n```\n </code></pre><script>\nif (!document.getElementById('syntaxed-prism')) {\n\tvar my_awesome_script = document.createElement('script');\n\tmy_awesome_script.setAttribute('src','https://beta.bluetab.net/wp-content/plugins/syntax-highlighter-for-elementor/assets/prism2.js');\n\tmy_awesome_script.setAttribute('id','syntaxed-prism');\n\tdocument.body.appendChild(my_awesome_script);\n} else {\n\twindow.Prism && Prism.highlightAll();\n}\n</script>\t\t</div>\n\t\t"}]} En esta prueba lo más relevante es que vamos a escribir los datos de la tablas customer(15000000 rows), orders(150000000 rows), supplier(1000000 rows), nation(25 rows) y region(5 rows) en nuestro bucket de GCS.
Como comentamos anteriormente, Starburst no solo es una herramienta que te permite lanzar consultas para analizar datos, sino que también te puede ayudar en las migraciones de datos de tu compañía, volcando la información de tu base de datos a tu plataforma de la nube. Una cosa muy importante a tener en cuenta es que Starburst te permite trabajar con distintos tipos de fichero, pudiendo escribir tus tablas finales en ORC, Parquet o formatos como Delta o Hudi dándote una libertad muy amplia en las migraciones al cloud.
Como última prueba para ver que todo está funcionando correctamente, vamos a lanzar una consulta para federar distintos datos de diversas fuentes. En nuestro caso, federaremos datos de la anterior tabla que hemos creado en Google Cloud Storage llamada customer con una tabla llamada nation, que nos crearemos en el PostgreSQL que hemos configurado en nuestro despliegue, y la tabla region que está en el esquema tcph. Esta consulta la podemos encontrar en el archivo `federate.sql`:
create schema postgres.logistic;
create table postgres.logistic.nation as select * from tpch.sf1.nation;
select
cst.name as CustomerName,
cst.address,
cst.phone,
cst.nationkey,
cst.acctbal as BookedOrders,
cst.mktsegment,
nat.name as Nation,
reg.name as Region
from hive.datalake.customer as cst
join postgres.logistic.nation as nat on nat.nationkey = cst.nationkey
join tpch.sf1.region as reg on reg.regionkey = nat.regionkey
where reg.regionkey = 1;
Este tipo de consultas es uno de los puntos fuertes que tiene Starburst, poder federar consultas que se encuentren en distintos silos de información sin la necesidad de migrar los datos y pudiendo atacar a distintos Cloud o a información que se tenga en el onpremise.
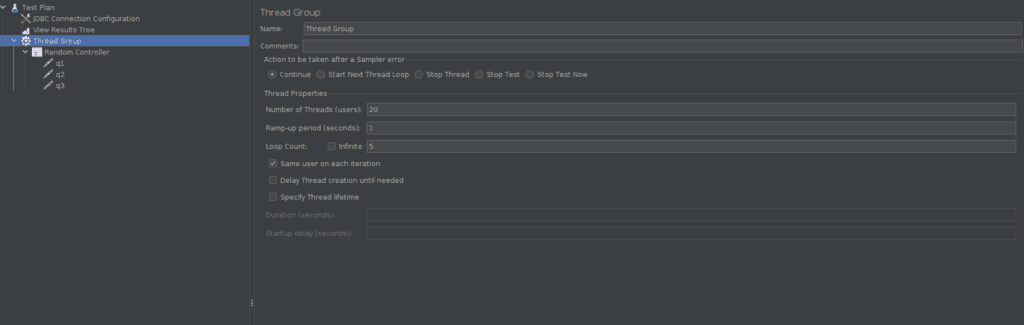
Una vez que hemos probado que tanto las consultas como la escritura en GCS funcionan correctamente, vamos a realizar unos test de performance para simular usuarios en paralelo y ver como autoescala nuestra plataforma. Vamos a configurar JMeter para estas pruebas. Para ello hemos tenido que configurar el conector jdbc de trino para que mande consultas a nuestro cluster.
Vamos a simular 20 usuarios en paralelo, y cada uno lanzará una secuencia de 5 consultas. Esto significa que habrá 20 consultas en paralelo al mismo tiempo, simulando un escenario real, ya que generalmente no se lanzarán consultas de todos los usuarios en el mismo momento. Las consultas que vamos a ejecutar son las siguiente:
```sql
select
cst.name as CustomerName,
cst.address,
cst.phone,
cst.nationkey,
cst.acctbal as BookedOrders,
cst.mktsegment,
nat.name as Nation,
reg.name as Region
from tpch.sf1.customer as cst
join tpch.sf1.nation as nat on nat.nationkey = cst.nationkey
join tpch.sf1.region as reg on reg.regionkey = nat.regionkey
where reg.regionkey = 1;
SELECT
s.acctbal
, s.name SupplierName
, n.name Nation
, p.partkey
, p.mfgr
, s.address
, s.phone
, s.comment
FROM
tpch.tiny.part p
, tpch.tiny.supplier s
, tpch.tiny.partsupp ps
, tpch.tiny.nation n
, tpch.tiny.region r
WHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (p.size = 15) AND (p.type LIKE '%BRASS') AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE') AND (ps.supplycost = (SELECT MIN(ps.supplycost)
FROM
tpch.tiny.partsupp ps
, tpch.tiny.supplier s
, tpch.tiny.nation n
, tpch.tiny.region r
WHERE ((p.partkey = ps.partkey) AND (s.suppkey = ps.suppkey) AND (s.nationkey = n.nationkey) AND (n.regionkey = r.regionkey) AND (r.name = 'EUROPE'))
)))
ORDER BY s.acctbal DESC, n.name ASC, s.name ASC, p.partkey ASC;
SELECT
count(*)
FROM
tpch.sf1.customer c
, tpch.sf1.orders o
, tpch.sf1.lineitem l
WHERE ((c.mktsegment = 'BUILDING') AND (c.custkey = o.custkey) AND (l.orderkey = o.orderkey))
GROUP BY l.orderkey, o.orderdate, o.shippriority
ORDER BY o.orderdate ASC;
```
Si nos fijamos, en nuestro cluster de Kubernetes podemos ver que se están levantando más workers de Starburst por el momento de alta demanda en nuestra simulación:

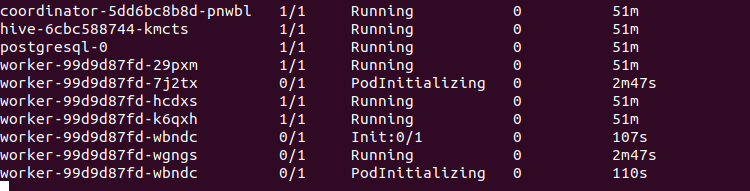
Esto es una de las características más cómodas e importantes que nos da Starburst, ya que hace que nuestra plataforma de analítica de datos sea 100% elástica y podamos ir adaptándonos a los picos de demanda que tengamos.
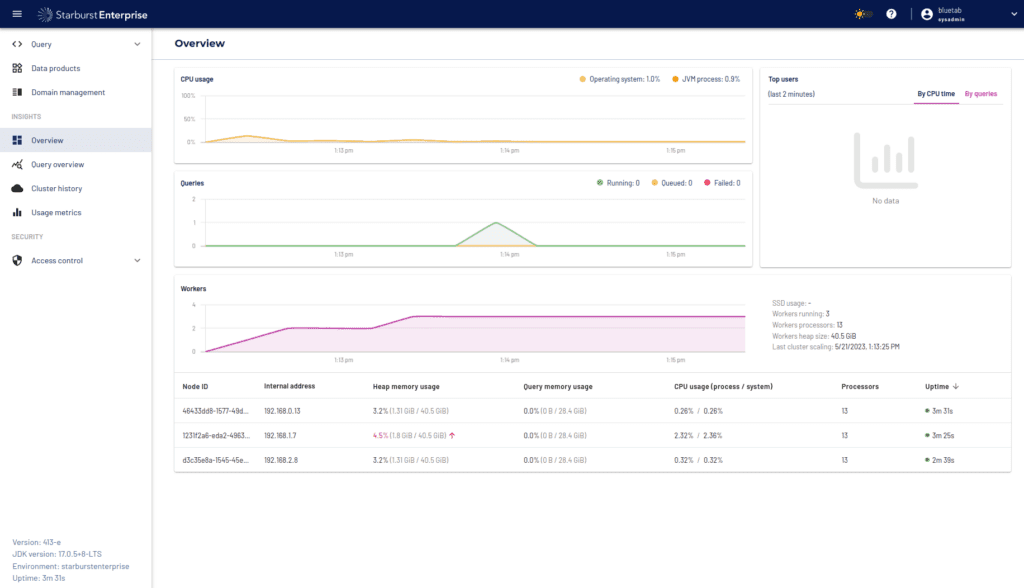
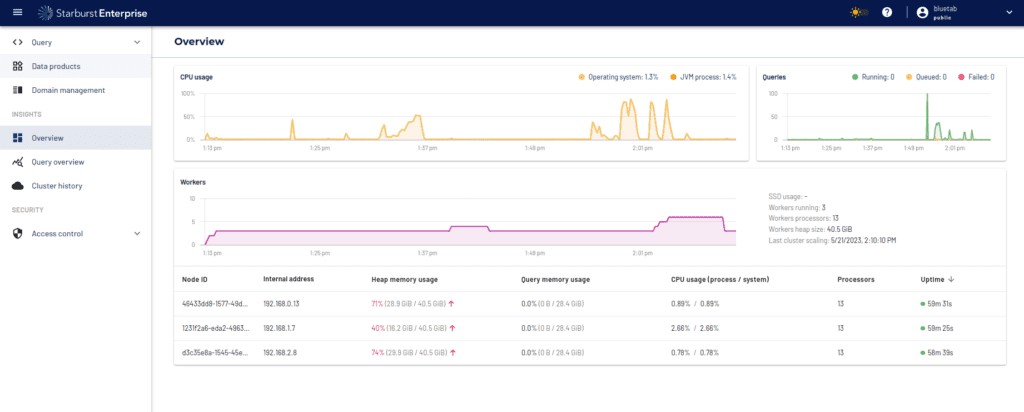
Por último, Starburst nos proporciona una interfaz donde visualizar ciertas métricas del consumo de nuestro cluster, como puede ser la memoria, la cpu o las consultas realizadas en tiempo real en nuestro cluster.
Además de estas métricas, hemos añadido también a nuestra configuración el despliegue de Prometheus y Grafana para integrarnos con las herramientas más comunes dentro de cualquier organización. Las métricas que hemos añadido a Grafana son consumo de memoria de nuestro cluster de Starburst, consultas realizadas por los usuarios, consultas con errores, memoria total de nuestro cluster de Kubernetes y Workers activos. Una vez integradas dichas métricas, el dashboard que tendríamos sería el siguiente:
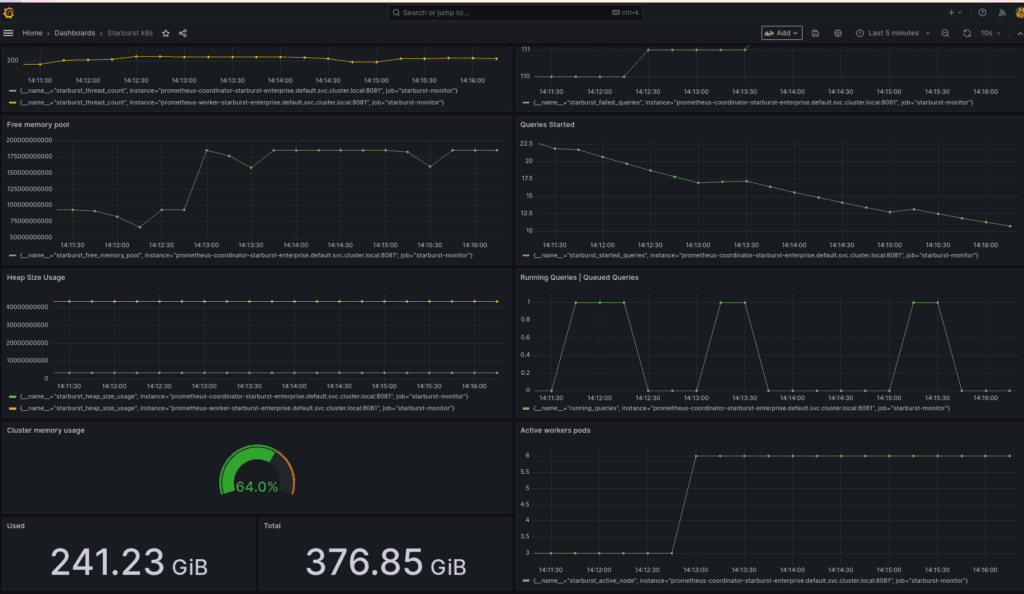
Una vez integrado con Grafana, podríamos crearnos alertas de envío de mensajes por si hay algún problema en nuestro cluster de Starburst, y así tener todo el flujo de operaciones cubierto para evitarnos dolores de cabeza si hubiera algún tipo de incidencia o indisponibilidad.
El dashboard está publicado en Grafana[14] para que cualquier persona pueda hacer uso de él.
Desde hace ya unos años, las grandes corporaciones se enfrentan a un desafío común cuando intentan compartir y analizar información entre departamentos ya que cada departamento almacena y gestiona sus datos de manera aislada. Estos silos dificultan el acceso y la integración de datos, lo que impide una visión completa y unificada de la información empresarial. La falta de interoperabilidad entre los silos de datos obstaculiza la toma de decisiones informada, ralentiza los procesos analíticos y limita la capacidad de las organizaciones para obtener una ventaja competitiva. Si tu organización se encuentra en una situación similar, Starburst es tu herramienta.
Starburst te facilita el acceso y análisis a todos estos silos de información y da la capacidad de federar datos de diversas fuentes y ubicaciones, ya sea datos en el Cloud o en tu datacenter onpremise. Permite realizar consultas en tiempo real sin necesidad de mover o transformar los datos previamente. Esto agiliza el proceso analítico y brinda a las organizaciones una visión 360 de sus datos. Además, no solo te ayuda a la hora de consultar datos de distintas fuentes, sino que también te puede ayudar en tus migraciones al Cloud, ya que te permite consultar cualquier origen y volcar dicha información en un almacenamiento como S3 o GCS en formato de ficheros abierto, como puede ser Parquet.
Una de las principales ventajas de Starburst, es que te permite desplegar la infraestructura en Kubernetes para aprovechar así todo su potencial. Kubernetes te da la capacidad de adaptarse dinámicamente a la carga de trabajo. Con esta función, los clústeres de Starburst pueden aumentar o disminuir automáticamente el número de Workers según la demanda. Esto permite optimizar el uso de recursos y garantizar un rendimiento óptimo, ya que los pods adicionales se crean cuando la carga aumenta y se eliminan cuando disminuye. Esto dentro de cualquier organización es un punto muy importante, ya que mejora la eficiencia operativa al minimizar el tiempo de inactividad y los costos innecesarios, al tiempo que asegura una disponibilidad constante y una respuesta ágil a los picos de trabajo. Además, una cosa a tener en cuenta es que puedes realizar la instalación de Starburst tanto en cualquiera de los Cloud, como en onpremise.
Además, también te permite tener un roleado y gobierno de los usuarios dentro de tu plataforma, dando una granularidad a nivel de acceso a los datos a cada usuario, permitiéndote crear roles para ciertos esquemas, tablas o hasta columnas y filas dentro de una tabla.
Los que trabajamos con datos sabemos de la dificultad de trabajar con multitud de fuentes de datos, entornos diversos, herramientas de todo tipo, etc. Uno de los puntos más diferenciales de Starburst es tener la capacidad de consultar los datos desde su almacenamiento, eliminando duplicidad de información, pudiendo así tener una mejor eficiencia en cuanto al storage, y facilitando también el gobierno de estos datos.
En conclusión, Starburst es una herramienta a tener en cuenta si quieres llevar a tu organización al siguiente nivel en el mundo de los datos, o si te estás planteando una estrategia de datos con una visión y una filosofía más orientada al data mesh.
[1] Qué es Starburst.[link]
[2] Qué es Trino. [link]
[3] Principios del Data Mesh. [link]
[4] Introducción a DBT. [link]
[5] Introducción a Jupyter Notebook. [link]
[6] Introducción a Power BI. [link]
[7] Qué es Prometheus.. [link]
[8] Qué es Grafana. [link]
[9] Qué es Terraform. [link]
[10] Qué es Jmeter.[link]
[11] Módulo de GKE.[link]
[12] Módulo de VPC.[link]
[13] Qué es TPCH.[link]
[14] Dashboard Grafana.[link]
[15] Repositorio de Github con el despliegue.[link]
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar




